Chapitre 5 - Le protocole HTTP
Toutes les communications réalisées entre un navigateur et un serveur web se font via le protocole HTTP. Ce protocole est un protocole de haut niveau qui est basé sur le protocole internet TCP (ou QUIC pour la version HTTP/3).
Une connaissance fine du protocole HTTP est nécessaire pour bien comprendre les interactions qu'il est possible de réaliser entre un navigateur et un serveur web.
Ce chapitre présente les principes de base du protocole HTTP. Il se focalise sur les requêtes GET et POST qui sont les requêtes les plus utilisées dans les applications web. Il détaille les mécanismes de transmission de l'information entre un client et un serveur.
Requête et réponse HTTP
Le protocole HTTP est un protocole de communication client-serveur : les échanges se font à l'initiative du client (le navigateur web), le serveur web se contente de répondre au client. Il n'est donc pas possible pour un serveur web d'envoyer une requête à un client web. Il faut pour cela utiliser un autre protocole comme par exemple les web sockets que nous ne présentons pas dans ce livre.
Le protocole HTTP est un protocole de type requête-réponse : le navigateur web envoie une requête au serveur web et le serveur web répond à cette requête. Le serveur web ne peut donc pas envoyer plus d'une réponse à une requête faite par un navigateur web. De fait, si un navigateur web veut obtenir plusieurs ressources, il faut alors qu'il envoie une requête par ressource. Il recevra chaque ressource dans une réponse différente.
Savoir que le protocole HTTP est client-serveur et requête-réponse permet de mieux comprendre la façon dont les interactions sont faites entre un navigateur web et un serveur web. Cela explique que l'affichage d'une page web contenant un mur d'images se fait en plusieurs requêtes. Une première requête est envoyée par le navigateur web dès que l'utilisateur a saisi l'URL du code HTML de la page web (le mode client-serveur impose une première interaction par l'utilisateur). Puis, une fois que le navigateur web a reçu le code HTML de la page web, il envoie autant de requêtes qu'il y a d'images référencées dans le code HTML (le mode requête-réponse impose l'envoi de plusieurs requêtes, même si cela peut se faire de manière transparente par le navigateur web).
Les requêtes et les réponses HTTP sont des messages textuels. Les requêtes sont structurées en trois parties :
- La commande qui est intégralement définie dans la première ligne de la requête. Une commande précise (1) le type de requête (GET, POST, etc.), (2) l'URL demandée et (3) la version du protocole supportée par le navigateur qui a émi la requête. Par exemple, la commande GET http://localhost:8080/public/index.html HTTP/1.1 (1) est de type GET, (2) demande la ressource index.html et (3) est conforme à la version 1.1 du standard HTTP.
- Les en-têtes qui contiennent des informations supplémentaires sur la requête. Par exemple, l'en-tête Accept:text/html indique que le navigateur web accepte de recevoir une réponse au format HTML. Les en-têtes sont définis dès la deuxième ligne de la requête sous forme de clé valeur (un en-tête par ligne). Il existe de nombreux en-têtes envoyés par les navigateurs pour optimiser leurs interactions avec les serveurs web. Nous en préciserons quelques uns dans la suite de ce chapitre.
- Le corps de la requête qui contient les données à envoyer au serveur web. Il est optionnel et n'est utilisé que par certains types de requêtes (POST et pas GET). Il est séparé des en-têtes par une ligne vide.
Le Code 5.1 présente un exemple de requête GET envoyée par un navigateur web pour obtenir une ressource dont l'URL est http://localhost:8080/public/index.html.
Cette requête contient un seul en-tête qui précise que le navigateur accepte les réponses sous format HTML.
GET http://localhost:8080/public/index.html HTTP/1.1
Accept: text/html
Code 5.1 : Un exemple de requête GET envoyée pour obtenir la page d'index.
Les réponses HTTP sont, quant à elles, composées des trois parties suivantes :
- La ligne de statut qui précise la version du protocole HTTP et définit le code de statut de la réponse. Par exemple, la ligne de statut HTTP/1.1 200 OK indique que la requête supporte la version 1.1 du standard HTTP et précise que la requête a été traitée avec succès (code 200). Il existe de nombreux codes de statut. Les plus connus étant le code 200 qui signifie que la requête a été traitée avec succès, le code 404 qui signifie que la ressource demandée n'a pas été trouvée et le code 500 qui signifie que le serveur est actuellement en erreur.
- Les en-têtes qui contiennent des informations supplémentaires sur la réponse. Les en-têtes Content-Length et Content-Type sont notamment utilisés pour donner des informations sur les données contenues dans le corps de la réponse.
- Le corps de la réponse qui contient les ressources retournées par le serveur web.
Le Code 5.2 présente un exemple de réponse. On voit que la réponse contient le code HTML de la page web demandée (les lignes 4 à 13 correspondent au corps de la réponse). Le code HTML est envoyé au navigateur web qui pourra l'afficher.
HTTP/1.1 OK 200
Content-Type: text/html
<!DOCTYPE html>
<html>
<body>
<h1>Bienvenue</h1>
<a href="images.html">Cliquez ici pour voir le mur des images</a>HTML
<div> <img src="image1_small.jpg"></div>
</body>
</html>
Code 5.2 : Un exemple de réponse à la requête précédente.
Le type d'une requête HTTP, qui est défini dans la partie commande de la requête, précise l'intention de la requête. Si le standard HTTP définit neuf types de requêtes, nous ne présentons que les deux plus utilisées : GET et POST. Les requêtes GET servent essentiellement à récupérer des ressources (GET = obtenir une ressource). Les requêtes POST sont, quant à elles, principalement utilisées pour envoyer des données vers le serveur web (POST = envoyer). Il faut noter d'ailleurs que les requêtes GET ne peuvent pas contenir de données dans leur corps alors que les requêtes POST le peuvent.
HTTP et navigateur web
Le protocole HTTP étant client-serveur, c'est au navigateur web d'initier toutes les communications avec le serveur. Cela peut se faire via la barre d'adresse du navigateur ou via les interactions supportées par HTML telles que les clics sur les liens hypertextes ou l'envoi de formulaire.
La barre d'adresse est le premier moyen d'interaction entre un utilisateur et un navigateur web. En saisissant, dans la barre d'adresse du navigateur, l'adresse de la page web qu'il souhaite afficher, l'utilisateur demande au navigateur d'envoyer une requête GET et d'afficher le résultat. Par exemple, si l'utilisateur saisit l'URL http://localhost:8080/public/index dans la barre d'adresse du navigateur, le navigateur va envoyer la requête GET présentée dans le code 5.1 . Si la réponse qu'il reçoit est celle du Code 5.2 , il va alors récupérer le code HTML du corps de cette réponse et afficher la page web correspondante.
Lorsque le navigateur reçoit une réponse HTTP qui contient du code HTML, il va identifier toutes les balises HTML qui référencent d'autres ressources et envoyer en parallèle autant de requêtes GET que nécessaire pour récupérer ces ressources, et ce avant d'afficher la page. Les balises qui référencent des ressources sont, par exemple, les balises : <img>, <video>, <link> et <script>. Dans notre exemple, la page d'index contient un lien vers une image. Le navigateur va donc envoyer une requête GET vers cette image pour l'afficher dans la page web.
Lorsqu'une page web est affichée, le navigateur attend que l'utilisateur interagisse avec elle pour envoyer d'autres requêtes. Il y a deux balises HTML qui supportent les interactions avec l'utilisateur, les balises : <a> et <form>.
La balise <a> est utilisée pour créer des liens hypertextes vers d'autres pages web. Leur attribut href spécifie l'URL de la page web cible. Lorsque l'utilisateur clique sur un lien hypertexte, le navigateur envoie une requête GET vers l'URL spécifiée dans l'attribut href de la balise <a>. Le code 5.3 montre un exemple de code HTML qui contient un lien hypertexte. Ce lien hypertexte pointe vers la ressource images.html qui est une page web contenant un mur d'images.
<!DOCTYPE html>
<html>
<body>
<h1>Bienvenue</h1>
<a href="images.html">Cliquez ici pour voir le mur d'images</a>
<div> <img src="image1_small.jpg"></div>
</body>
</html>
Code 5.3 : Un exemple de lien hypertexte.
La Figure 5.1 montre l'affichage de la page web dans un navigateur web. L'utilisateur peut cliquer sur le lien hypertexte pour accéder à la page web images.html.
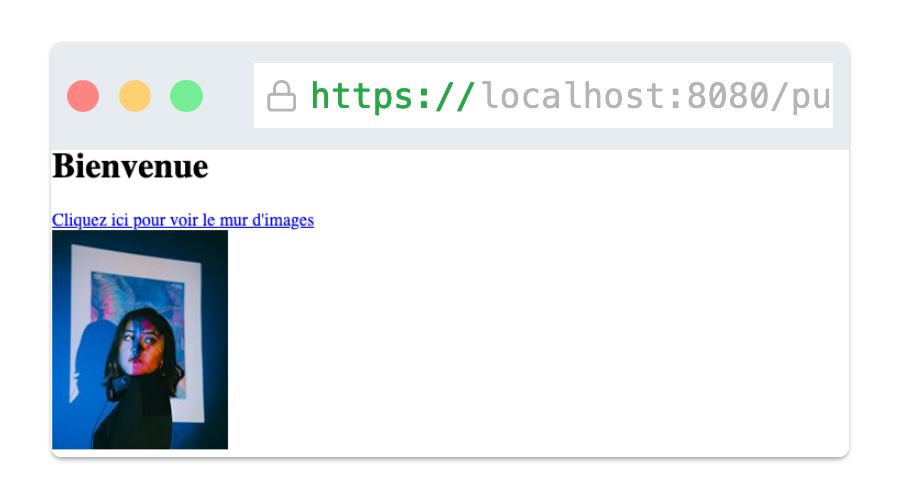
Figure 5.1 : Affichage du lien hypertexte de la page web dont le code HTML est celui du Code 5.3.
Quand tout se passe bien, une réponse à un clic sur un lien hypertexte a 200 comme code de statut et contient la ressource demandée dans son corps. Un navigateur qui reçoit une telle réponse affiche alors la ressource demandée. La Figure 5.2 présente le résultat de l'interaction entre l'utilisateur et le navigateur web après avoir cliqué sur le lien hypertexte de la page index.
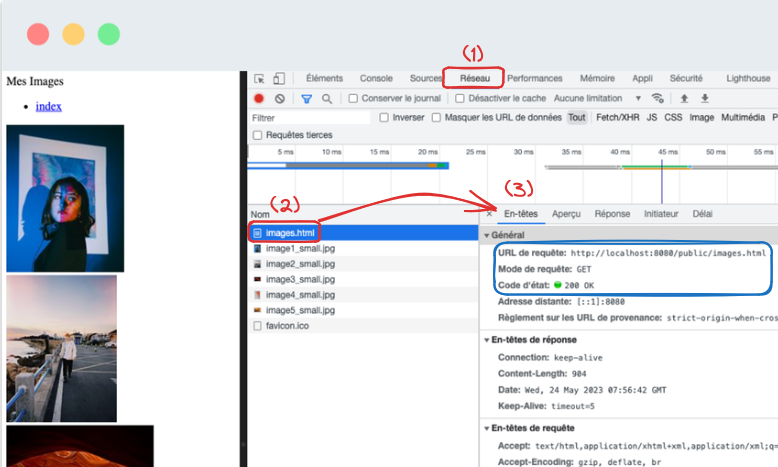
Figure 5.2 : Le navigateur après avoir cliqué sur le lien hypertexte.
La figure montre les outils de développement et plus précisément les échanges réseau. On peut voir les différentes requêtes et réponses échangées entre le navigateur et le serveur web. La figure présente des détails sur la première requête envoyée : celle vers le code HTML de la page. On peut voir que cette requête est une requête GET et que son URL est http://localhost:8080/public/images.html. La réponse a un code de statut de 200. Son corps contient le code HTML de la page web images.html. Les autres requêtes et réponses présentées dans la figure sont des requêtes et réponses pour récupérer les ressources (images, CSS, JavaScript) qui sont référencées dans le code HTML de la page web.
La deuxième balise HTML qui permet à un utilisateur d'interagir avec un navigateur web et de lui demander d'envoyer une requête est la balise <form>. La balise <form> permet d'afficher un formulaire invitant l'utilisateur à saisir des données et à les envoyer au serveur web. Les informations faisant parties du formulaire sont déclarées dans des balises <input> à l'intérieur du formulaire. Chaque balise <input> peut définir le type de champ (texte, mot de passe, etc.) et le nom de la variable qui contiendra la valeur saisie par l'utilisateur. Enfin, un formulaire doit contenir un bouton (balise <input> dont l'attribut type vaut submit) qui permet de soumettre le formulaire.
Par exemple, le Code 5.4 présente une page web qui contient un formulaire. La soumission de ce formulaire permet à l'utilisateur de saisir un numéro d'image et une description pour cette image.
<!DOCTYPE html>
<html>
<body>
<h1>Description Image</h1>
<form action="/description-image" method="post">
<input type="number" name="image-number">
<input type="text" name="description">
<input type="submit" value="Envoyer">
</form>
</body>
</html>
Code 5.4 : Un exemple de formulaire HTML.
La soumission d'un formulaire demande au navigateur d'envoyer une requête contenant les données saisies par l'utilisateur vers le serveur web. La balise <form> déclare l'URL cible de la soumission dans l'attribut action et le type de requête dans l'attribut method (POST ou GET). Si l'attribut method de la balise <form> a pour valeur POST, la requête est de type POST. Dans ce cas le navigateur envoie les données dans le corps de la requête. Il est même possible de préciser l'encodage des données avec l'attribut enctype du formulaire. Par défaut les données sont encodées comme des paramètres d'une URL. Si, par contre, la valeur de l'attribut method est GET, la requête est de type GET. Dans ce cas le navigateur ajoute les données à l'URL de la requête. Le code 5.5 présente un exemple de requête POST envoyée par le navigateur après la soumission du formulaire du code 5.4 . Le code 5.6 présente un exemple de requête GET envoyé pour la même soumission du formulaire.
Ces deux exemples de code montrent la façon par défaut dont sont encodées les données lors d'une soumission de formulaire.
POST http://localhost:8080/description HTTP/1.1
Accept: text/html
image-number=1&description=top
Code 5.5 : Un exemple de requête POST envoyée avec les données d'un formulaire. Les données sont encodées dans le corps de la requête.
GET http://localhost:8080/description?image-number=1&description=top HTTP/1.1
Accept: text/html
Code 5.6 : Un exemple de requête GET envoyée avec les données d'un formulaire. Les données sont encodées dans l'URL de la requête.
Le choix entre POST et GET pour un formulaire se fait en fonction de la nature des données à envoyer. Dès que les données sont complexes ou même trop volumineuses, il est préférable d'utiliser POST. En effet, l'encodage de données dans une URL est contraint par la taille : une URL peut avoir une taille maximale de 2083 caractères.
La connaisssance du protocole HTTP permet enfin de mieux comprendre comment un navigateur construit les URLs des requêtes qu'il doit envoyer. Toutes les requêtes envoyées par un navigateur doivent avoir une URL complète qui précise l'adresse du serveur, son port et le chemin de la ressource cible (voir Chapitre 1). Ces URLs complètes sont construites à partir des URLs contenues dans les balises HTML (balises <a>, <form>, <img>, <link>, etc.). En effet, il n'est pas nécessaire de définir des URLs complètes dans ces balises, on peut, et c'est même conseillé mettre des URL absolues ou relatives.
Une URL absolue définit un chemin qui commence par le caractère "/". Par exemple /public/image1_small.jpg est une URL absolue. Une URL absolue ne contient pas de protocole, d'adresse du serveur ni de port. Pour construire une URL complète à partir d'une URL absolue le navigateur réutilise l'URL de la page courante et récupère le protocole, l'adresse du serveur et le port. Par exemple, si l'URL de la page courante est http://localhost:8080/public/test-url alors on récupère le protocole http, l'adresse du serveur localhost et le port 8080. L'URL asbolue /public/image1_small.jpg deviendra l'URL complète http://localhost:8080/public/image1_small.jpg
Une URL relative définit quant à elle un chemin relatif qui ne commence pas par le caractère "/". Par exemple, image1_small.jpg est une URL relative. Une URL relative ne contient pas de protocole, d'adresse du serveur ni de port. Pour construire une URL complète à partir d'une URL relative le navigateur prend l'URL de la page actuelle, récupère son protocole, son adresse du serveur, son port et son chemin jusqu'au dernier /. Par exemple, si l'URL de la page courante est http://localhost:8080/public/test-url alors on récupère le protocole http, l'adresse du serveur localhost, le port 8080 et le chemin /public/ (jusqu'au dernier / donc on ne récupère pas test-url). L'URL relative image1_small.jpg deviendra l'URL complète http://localhost:8080/public/image1_small.jpg
A titre d'exemple, le Code 5.7 présente une page web qui a été obtenue via l'URL http://localhost:8080/public/test-url. Cette page contient trois balises <img> avec les trois types d'URL : complète, absolue et relative. Avant d'envoyer les requête GET pour récupérer les images, le navigateur va donc construire les URLs complètes. Il n'a rien à faire pour la première URL qui est une URL complète. Pour la deuxième URL, il réutilise le protocole, l'adresse du serveur et son port. Pour la troisième URL, il réutilise le protocole, l'adresse du serveur, son port ainsi que le chemin vers la ressource courante. Avec notre exemple, le navigateur va construire trois URLs qui vont toutes êtres les mêmes : http://localhost:8080/public/image1_small.jpg. Notons pour information qu'un navigateur moderne qui fera face à cette situation va se rendre compte qu'une seule et même ressource est demandée, il ne va alors envoyer qu'une seule requête GET pour récupérer l'image.
{kind=link}
<!DOCTYPE html>
<html>
<body>
<h1>Bienvenue</h1>
<h2>URL complete</h2>
<img src="http://localhost:8080/public/image1_small.jpg">
<h2>URL absolue</h2>
<img src="/public/image1_small.jpg">
<h2>URL relative</h2>
<img src="image1_small.jpg">
</body>
</html>
Code 5.7 : Un exemple de page HTML qui contient des URLs complètes, absolues et relatives.
Enfin, connaître le protocole HTTP permet de bien comprendre le fonctionnement des navigateurs web lorqsu'ils reçoivent les réponses des serveurs web. Nous l'avons mentionné en début de chapitre, le protcole HTTP définit un code de statut qui permet de savoir dans la réponse si le traitement demandé par la requête s'est bien passé ou pas. Un code de statut est un code à trois chiffres (xxx). Le chiffre de la centaine exprime la sémantique de la réponse. Les codes 2xx sont des codes de succès. Le navigateur qui reçoit une telle réponse sait qu'il trouvera la réponse à sa requête dans le corps de la réponse. Le code le plus connu est le code 200 qui exprime un succès total de la requête. Les codes 3xx sont des codes à redirection. Le navigateur qui reçoit une telle réponse sait qu'il doit faire de nouvelles requêtes pour que sa requête soit traitée. Le code le plus connu est le code 302 qui demande au navigateur de faire une nouvelle requête vers une nouvelle URL qui est précisée dans l'en-tête de la réponse nommée Location. Les codes 4xx sont des codes d'erreur du côté du navigateur web. Le code le plus connu est le code 404 qui explique au navigateur que la ressource demandée n'existe pas. Enfin, les code 5xx sont des codes d'erreur du côté du serveur web. Le code le 500 exprime une erreur interne au serveur.
HTTP et serveur web
Les serveurs web doivent être capables de traiter toutes les requêtes HTTP qui leur sont envoyées, que celles-ci soient de type GET ou POST. Ils doivent être capables de différencier les requêtes en fonction de leur type et de leur URL. Ils doivent aussi être capables de récupérer les informations transmises dans les requêtes, que ces informations soient encodées dans les URLs ou dans le corps des requêtes. Enfin, ils doivent renvoyer les réponses qui correspondent aux requêtes reçues.
Le Code 5.8 présente un serveur qui traite les requêtes POST et GET. Ce serveur reprend le Code 4.1 du serveur statique. Les lignes 9 à 16 correspondent au traitement des ressources statiques. Par rapport au Code 4.1, la ligne 9 ajoute un test pour vérifier que la requête est bien de type GET. Les lignes 17 à 29 sont complètement nouvelles. Elles correspondent au traitement du formulaire présenté dans le Code 5.4. La ligne 17 vérifie que la requête est bien de type POST et que l'URL est bien /description-image. Les lignes 18 à 28 récupèrent les données contenues dans le corps de la requête, ajoutent ces données dans le tableau descriptions qui a été défini à la ligne 7, et retournent une réponse avec un code 200 qui contient le tableau des descriptions en format texte.
const fs = require("fs");
const http = require("http");
const host = 'localhost';
const port = 8080;
const server = http.createServer();
const descriptions = [];
server.on("request", (req, res) => {
if (req.method === 'GET' && req.url.startsWith('/public/')) {
try {
const fichier = fs.readFileSync('.'+req.url);
res.end(fichier);
} catch (err) {
console.log(err);
res.end("erreur ressource");
}
} else if (req.method === "POST" && req.url === "/description-image") {
let donnees;;
req.on("data", (dataChunk) => {
donnees += dataChunk.toString();
});
req.on("end", () => {
const paramValeur = donnees.split("&");
const imageNumber = paramValeur[0].split("=")[1];
const description = paramValeur[1].split("=")[1];
descriptions[imageNumber] = description;
res.statusCode = 200;
res.end(descriptions.toString());
});
}
else {
res.end("erreur URL");
}
});
server.listen(port, host, () => {
console.log(`Server running at http://${host}:${port}/`);
});
Code 5.8 : Un serveur qui traite un formulaire.
Ce chapitre présente le protocole HTTP. Trois points sont à retenir :
- HTTP est un protocole client-serveur et requête-réponse. Les messages échangés sont des messages textuels composés de trois parties (statut, en-tête et corps).
- Le navigateur web est à l'initiative de la communication. Il envoie des requêtes lorsque l'utilisateur utilise la barre de navigation, lorsqu'il reçoit un code HTML qui référence d'autres ressources, et quand l'utilisateur interagit via les balises
<a>et<form>. - Le serveur web reçoit les requêtes qui lui sont envoyées. Il peut différencier les requêtes en fonction de leur type et de leur URL. Il est capable de retrouver les informations qui ont été encodées dans les requêtes. Enfin, il renvoie des réponses en précisant le code de retour et le contenu de la réponse.
Pour s'exercer
Questions de cours
HTTP est un protocole client-serveur parce que ?
- a) Les interactions se font entre les clients et les serveurs.
- b) Les interactions sont toujours à l'initiative du client.
- c) Les interactions sont toujours à l'initiative du serveur.
HTTP est un protocole requête réponse parce que ?
- a) Il y a une et une seule réponse par requête.
- b) Il y a une réponse pour plusieurs requêtes.
- c) Il y a plusieurs réponses pour une seule requête.
Les requêtes HTTP sont encodées sous quelle forme ?
- a) Binaire (chaine d'octets).
- b) De document JSON (arbre avec des balises).
- c) De texte (chaine de caractères).
Pour récupérer une page web, le navigateur web doit envoyer combien de requêtes ?
- a) Une requête par ressource composant la page web.
- b) Une seule requête pour toutes les ressources qui composent la page.
- c) Une seule requête, c'est le serveur qui envoie autant de réponses qu'il y a de ressources.
Est-il possible pour le navigateur d'envoyer des informations avec un requête GET ?
- a) Non, il faut utiliser une requête POST.
- b) Oui, mais uniquement dans le corps de la requête GET.
- c) Oui, mais uniquement dans l'URL de la requête (dans le chemin ou les paramètres).
Réponses: 1-b, 2-a, 3-c, 4-a, 5-c
Exercice 1 - Formulaire Login
L'objectif est de créer une application web qui propose un simple formulaire de connexion.
Créez un répertoire chap5-exercice1 dans lequel vous allez créer trois fichiers : server.js, index.html et login.html. Le fichier server.js contiendra le code de votre serveur web. Le fichier index.html contiendra le code de la page web d'accueil. Le code login.html contiendra le code du formulaire de connexion.
Codez le serveur server.js pour qu'il fournisse la page index.html et la page login.html.
Codez la page web index.html pour qu'elle affiche une référence vers la page login.html ce qui permettra de se connecter.
Codez la page web login.html pour qu'elle affiche un formulaire de connexion.
Codez la soumission du formulaire de connexion. On considère que le serveur connait le login / password de plusieurs utilisateurs (stockés en dur dans le code du serveur). Si le login/password soumis est correct alors le serveur retourne une page d'accueil avec un message de bienvenue. Sinon, il retourne une page d'erreur.
Projet - mur d'images
Nous allons reprendre notre projet qui permet d'afficher des images (voir Chapitre 4, projet).
On souhaite maintenant permettre à l'utilisateur d'ajouter des commentaires et des likes sur les images. Vous pouvez voir le résultat attendu ici.
Récupérez le code que vous avez réalisé dans le chapitre 4 et copiez-le dans un nouveau répertoire nommé chap5-projet.
Créez une nouvelle page web (image-description.html) qui soit accessible statiquement et qui contienne un formulaire HTML permettant de saisir un commentaire sur une image. Le formulaire doit contenir les champs suivants:
- un champ pour saisir le numéro de l'image à commenter,
- un champ de saisie de texte pour le commentaire,
- un bouton de validation.
La soumission du commentaire doit être effectuée en utilisant la méthode HTTP POST.
L'URL cible du commentaire doit être
/image-description.Faites en sorte que la page web
image-description.htmlsoit accessible via un lien hypertexte dans le mur d'images (en haut, avant les images).Ajoutez une nouvelle route dans le serveur web pour traiter les requêtes POST sur l'URL
/image-description. Cette route doit récupérer les valeurs saisies dans le formulaire et les afficher dans la console du serveur web. Pensez à utiliser la fonction JS console.log() pour l'affichage dans la console.Elle doit aussi ajouter le commentaire dans un tableau de commentaires dans le serveur web.
Enfin, elle doit renvoyer une page dynamique indiquant que le commentaire a bien été ajouté.
Modifiez la génération dynamique des pages de chaque image (/page-image/1, /page-image/2, etc.) pour que les commentaires soient affichés sous l'image de cette page.
Reprenez votre code pour que le formulaire de commentaires ne soit plus fourni statiquement mais qu'il soit intégré dynamiquement dans les pages de chaque image. L'objectif est de pouvoir commenter l'image lorsqu'on la regarde. Il faudra alors veiller à modifier le formulaire car l'utilisateur ne doit pas saisir l'id de la image.
Modifiez le traitement de la soumission d'un nouveau commentaire pour que le serveur renvoie une demande de redirection au navigateur vers la page qui affiche l'image (et non plus une page qui précise que le commentaire a été ajouté). Il faut que le serveur renvoie une réponse avec 302 comme code de statut et qu'il précise dans l'en-tête l'URL de la page cible. Le code suivant présente un exemple de redirection vers la page index.
res.statusCode = 302;
res.setHeader('Location', '/index.html');
res.end();