Chapitre 1 - Serveur de pages Web
Le web est devenu incontournable. Toutes les applications que nous utilisons se trouvent aujourd'hui sur le web.
Ce chapitre présente les fondamentaux du web. Il donne des définitions aux concepts de base. Il explique que les pages web sont fournies par des serveurs web et que les navigateurs web permettent d'y accéder. Il détaille enfin la notion d'URL et présente le rôle du standard HTTP.
Tous les concepts présentés sont illustrés par la construction d'un tout petit serveur web capable de fournir deux pages web. Vous pourrez développer ce serveur et l'exécuter sur votre ordinateur.
Pages web, serveur web et navigateur web
Le web est souvent représenté par une toile d'araignée où chaque noeud est une page web. Les fils de la toile illustrent la navigation de proche en proche entre les pages web : on visite une première page, puis en suivant un lien on visite une deuxième page web, et ainsi de suite.
Cette représentation très imagée fait une impasse complète sur les concepts de ressources web et de serveur web qui sont pourtant incontournables. Elle occulte le fait qu'une page web est constituée de plusieurs ressources (page HTML, images, feuille de style CSS, Javascript) ; chacune fournie indépendamment par les serveurs web. Nous préférons donner les définitions suivantes :
- Une page web est affichée par un navigateur web qui, pour se faire, doit récupérer toutes les ressources qui la composent.
- Une page web est constituée de ressources qui sont nécessaires à son affichage (son code HTML, des feuilles de style, des images, du code javascript, etc.).
- Un serveur web est un programme qui s'exécute sur un ordinateur accessible sur internet et qui fournit des ressources constituant des pages web.
- Un navigateur web est un programme qui s'exécute sur un ordinateur et qui affiche des pages web en demandant aux serveurs web les ressources qui composent celles-ci.
La Figure 1.1 donne une illustration graphique de notre définition du web. Elle présente deux ordinateurs connectés à Internet. L'ordinateur de gauche a un navigateur web qui permet à ses utilisateurs de visualiser des pages web en accédant aux ressources fournies par le serveur web. L'ordinateur de droite exécute un serveur web et fournit ainsi des ressources qui composent des pages web. Notons que le navigateur web et le serveur web communiquent sur Internet grâce au protocole HTTP.
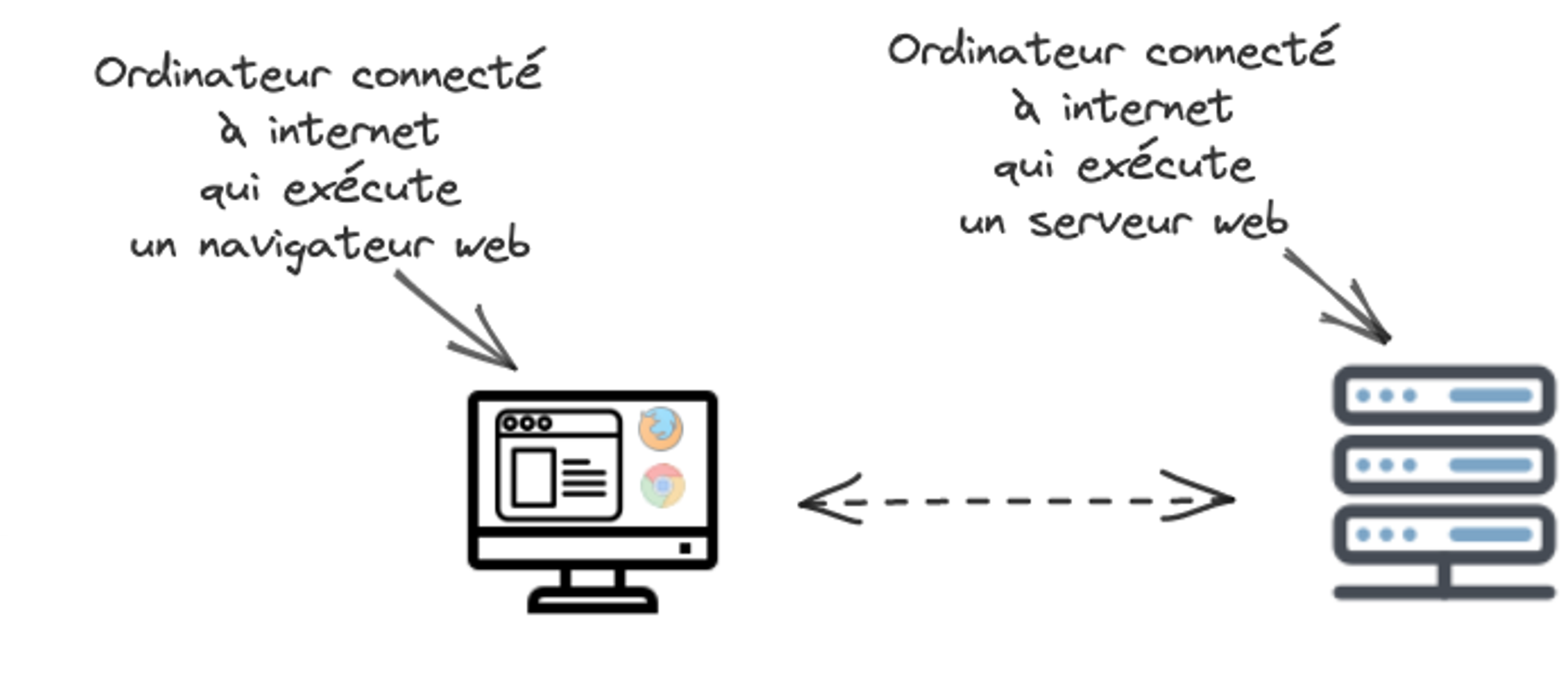
Figure 1.1 : Un navigateur web (à gauche) qui récupère des ressources pour afficher des pages web. Un serveur web (à droite) qui fournit des ressources composants des pages web.
Nos définitions mettent en avant les concepts de ressource web, de page web, de serveur web et de navigateur web. Elles insistent aussi sur le fait que les navigateurs et les serveurs web sont des programmes qui s'exécutent sur des ordinateurs accessibles sur Internet. Les serveurs web fournissent des ressources aux ordinateurs connectés à Internet qui utilisent un navigateur web. Les navigateurs affichent les pages web en demandant les ressources qui les composent. Cela nous permet de donner une définition complète du web :
Le plus petit serveur web
Le plus petit serveur web qu'il soit possible de construire permet l'affichage d'une unique page web qui est composée d'une seule ressource (un document HTML). Le développement de ce serveur web nécessite le développement de deux composants :
- L'unique ressource fournie par le serveur web (le code HTML)
- Le programme qui répond aux requêtes des navigateurs web (le code de ce programme).
La page web affichée est extrêmement simple. Elle présente uniquement le texte suivant : "Bonjour, c'est la seule page que j'ai !". Elle n'est constituée que d'une seule ressource qui est son code HTML (fichier index.html). Le Code 1.1 présente ce code HTML.
<!DOCTYPE html>
<html lang="fr">
<head>
<title>Petite page web</title>
</head>
<body>
Bonjour, c'est la seule page que j'ai !
</body>
</html>
Code 1.1 : La page
Le programme de notre plus petit serveur web doit répondre aux requêtes des navigateurs web et leur renvoyer la ressource de son unique page web (le code HTML de la page web). Le Code 1.2 présente le code de ce serveur en NodeJS (fichier server.js).
- Les deux premières lignes construisent le serveur web. La construction d'un serveur web s'effectue en appelant la fonction createServer() de l'API http de NodeJS. Cette fonction renvoie un objet qui représente le serveur. Notre code définit la constante nommée server pour référencer cet objet.
- Les lignes 4 à 8 précisent le comportement du serveur lorsqu'il est démarré. Il se tient prêt à recevoir une requête HTTP. Dès qu'il en reçoit une, il renvoie le code HTML (Code 1.1) comme réponse. Le navigateur pourra alors afficher cette page. Pour coder le comportement du serveur nous utilisons la méthode on. Celle-ci a deux arguments. Le premier est le type d'événement. Dans notre cas, nous souhaitons préciser le comportement du serveur quand il reçoit une requête : le premier paramètre est donc request. Le deuxième paramètre est une fonction prenant deux paramètres (la requête et la réponse). Cette fonction est exécutée à chaque fois que le serveur reçoit une requête. Dans notre cas, cette fonction lit le fichier index.html en utilisant la fonction readFileSync de l'API fs (fs pour filesystem), puis utilise la méthode end qui envoie la réponse à la requête du navigateur web et termine le traitement.
- Les lignes 10 à 13 démarrent le serveur web en précisant son port (8080) et son adresse (localhost). Cela se fait en utilisant la méthode listen de l'objet serveur. Cette méthode accepte trois paramètres. Les deux premiers spécifient le port et l'adresse du serveur. Le troisième est une fonction qui s'exécute dès que le serveur est en marche. Dans notre cas, nous faisons apparaître un simple message sur la console.
const http = require("http");
const server = http.createServer();
const fs = require("fs");
server.on("request", (request, response) => {
const indexPage = fs.readFileSync("./index.html", "utf-8");
response.end(indexPage);
});
const port = 8080;
server.listen(port, () => {
console.log("Server running");
});
Code 1.2 : Le serveur
Les deux fichiers (index.html et server.js) constituent le code de notre plus petit serveur web. Pour démarrer le serveur, il suffit d'exécuter le fichier (server.js) en utilisant NodeJS. Il faut que les fichiers index.html et server.js soient copiés dans un même répertoire, puis il faut lancer la commande suivante dans un terminal (powershell sous windows ou shell sous linux) dans ce même répertoire:
node server.js
Code 1.3 : Commande pour démarrer le serveur web.
L'exécution de notre plus petit serveur web devrait afficher "Server running" sur la console. Pour le tester on peut ouvrir un navigateur web sur le même ordinateur qui exécute le serveur web et ouvrir la page http://localhost:8080. Le navigateur va alors récupérer la ressource et afficher la page web.
Naviguer dans les pages d'un serveur : Comprendre les URL et HTTP
La navigation sur le web consiste à utiliser un navigateur web et lui dire quelle page on veut visiter. Cela se fait en précisant la localisation exacte de la page, c'est-à-dire en donnant l'adresse du serveur qui fournit cette page et en identifiant la ressource principale de cette page (son code HTML). Toutes ces informations (adresse du serveur et identification de la page) sont représentées par l'URL (Uniform Resource Locator) de la page que l'on veut visiter.
En tant qu'utilisateur du web, nous manipulons quotidiennement les URLs. Par exemple, l'URL de Google est https://www.google.com et celle du W3C (consortium qui définit les standards du web, https://www.w3.org/). Ces URL référencent les codes HTML des pages de google et du W3C.
Comprendre la structure de l'URL est essentiel pour comprendre comment la navigation sur le web fonctionne. Une URL est composée de six parties. Les cinq premières parties localise précisément la ressource, la sixième partie est exploitée en interne par le navigateur pour pointer une sous-partie de la ressource. Voici une description précise des six parties des URLS :
- Le protocole : Les URLs sont utilisées pour identifier des ressources qui sont fournies par des serveurs sur Internet. La première partie de l'URL précise quel protocole internet doit être utilisé pour accéder à la ressource. Dans le cas des pages web, il y a deux protocoles possibles : HTTP ou HTTPS (S pour sécurisé).
- L'adresse IPv4 de l'ordinateur qui exécute le serveur web ou son nom DNS : Un serveur web est exécuté sur un ordinateur qui est connecté à Internet. Localiser une ressource web nécessite de localiser son serveur web et donc l'ordinateur qui l'exécute. Cela peut se faire en précisant son adresse IPv4 ou son nom de domaine.
- Le port de l'ordinateur : Un serveur web est un programme qui est exécuté sur un ordinateur. Ce programme accepte des requêtes Internet. Pour se faire, il doit ouvrir un port de communication sur l'ordinateur. L'URL peut (cette partie est optionnelle) préciser le port du serveur web. Par défaut, si le port n'est pas précisé dans l'URL, le port HTTP est le port 80 et le port HTTPS est le port 443.
- Le chemin de la ressource : Un serveur web peut proposer de nombreuses ressources web. On distingue les ressources web en donnant leur chemin web. Un chemin web est composé de noms séparés par le caractère "/". Attention un chemin web est différent d'un chemin d'accès à un fichier.
- Les paramètres : La localisation d'une ressource web peut nécessiter la définition de paramètres. Une URL peut contenir les paramètres. Chaque paramètre est défini par une clé et une valeur (séparées par le caractère "="). Deux paramètres sont séparés par le caractère "&".
- L'ancre : Une page web peut contenir des sous-parties localisables (des paragraphes par exemple). Une URL peut identifier une sous-partie afin de faciliter son affichage par le navigateur (pour aller directement à un paragraphe par exemple).
Notons qu'une URL est représentée par une chaîne de caractères. Des caractères spéciaux sont utilisés pour distinguer les six parties qui la composent :
- Le protocole (http ou https) termine par les caractères "://"
- Le port commence par le caractère ":"
- Le chemin commence par le caractère "/"
- La liste des paramètres commencent par le caractère "?"
- L'ancre commence par le caractère "#"
Ainsi, les URLs suivantes sont composées de cette manière :

Nous avons vu que la première partie d'une URL précise le protocole utilisé. Dans le cas du web, c'est HTTP (Hypertext Transfer Protocol) qui est utilisé pour établir les communications entre les navigateurs web et les serveurs web (avec HTTPS pour la version sécurisée). Dès qu'une URL est demandée dans un navigateur web, une requête HTTP est envoyée vers le serveur pointé par la première partie de l'URL. Cette requête peut demander différentes actions au serveur web comme récupérer une page web (GET) ou envoyer des informations (POST). Une fois la requête reçue, le serveur la traite et renvoie une réponse HTTP. Cette réponse comprend un code de statut indiquant si la requête a réussi (par exemple, 200 pour succès) ou non (par exemple, 404 pour "non trouvé"), ainsi que les données demandées. Le chapitre 5 présente plus de détails sur ce protocole HTTP.
La Figure 1.2 illustre la manière dont le navigateur et le serveur web communiquent. L'utilisateur ouvre d'abord un navigateur web et saisit l'URL http://localhost:8080. Le navigateur envoie alors une requête HTTP pour demander la ressource correspondante (nous donnerons plus de détails sur le protocole HTTP dans le chapitre 5). Le serveur lui renvoie la réponse (le code HTML). Le navigateur peut alors afficher la page.
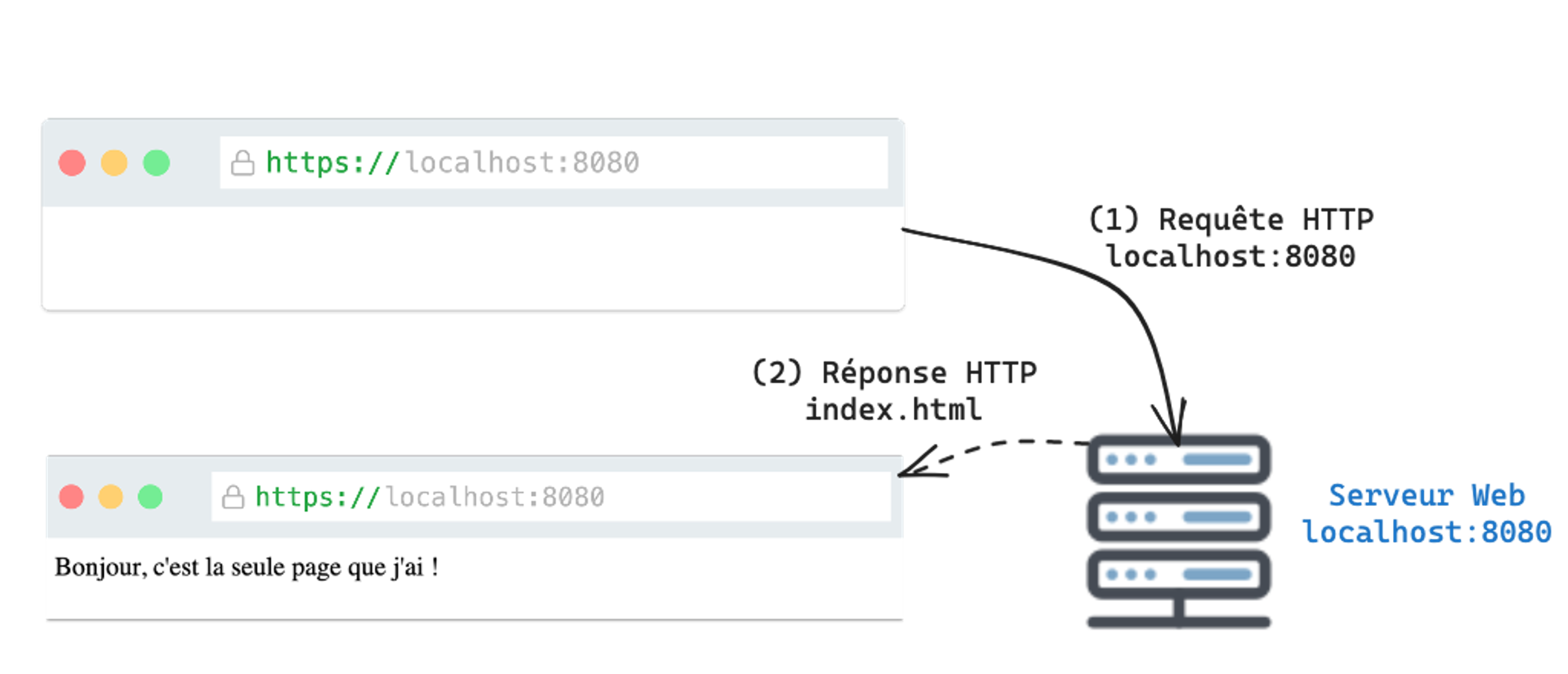
Figure 1.2 : La page web de notre plus petit serveur.
Un serveur web avec 2 pages
Pour illustrer la navigation de proche en proche entre les pages web nous allons maintenant ajouter une deuxième page web à notre serveur web. Plus précisément, nous allons faire en sorte qu'il soit possible de naviguer de la première page vers la deuxième page.
Le développement de ce nouveau serveur nécessite (1) de modifier la première page web pour qu'elle pointe vers la deuxième page, (2) de construire la deuxième page, et (3) de modifier le programme du serveur web pour qu'il renvoie la première page ou la deuxième en fonction des requêtes émises par les navigateurs web.
La modification de la première page consiste à intégrer un lien web vers la deuxième page.
Le moyen le plus simple est d'utiliser la balise HTML <a> dont l'attribut href précise soit l'URL complète de cette deuxième page soit uniquement la partie chemin web de cette URL.
Cette balise peut contenir du texte.
Si c'est le cas, le navigateur rendra ce texte cliquable et fera en sorte qu'un clic demande l'affichage de la page cible.
Le Code 1.4 présente le code HTML de la nouvelle page web.
La ligne 8 contient le lien web vers la deuxième page.
Il est important de noter que nous avons choisi de ne donner que le chemin de la deuxième page web (et non son URL complète). Cela indique que la deuxième page est hébergée sur le même serveur web (même protocole, même nom DNS, même port). De plus, nous avons choisi page2 comme chemin. Ce choix est totalement arbitraire et n'est pas lié au nom du fichier (que nous appellerons page2.html). Même si nous aurions pu faire un choix différent, celui-ci est, à notre avis, plus clair et plus facile à comprendre.
<!DOCTYPE html>
<html lang="fr">
<head>
<title>Index</title>
</head>
<body>
Bonjour, c'est la seule page que j'ai !
<a href="page2">Cliquez ici pour afficher la page 2</a>
</body>
</html>
Code 1.4 : Le code source modifié de la page index.html avec un lien vers la page 2.
Le Code 1.5 présente le code HTML de la deuxième page. Ce code ne présente pas de nouveauté. Cette page affiche simplement "C'est la page 2 !".
<!DOCTYPE html>
<html lang="fr">
<head>
<title>Index</title>
</head>
<body>
C'est la page 2 !
</body>
</html>
Code 1.5 : Le code source de la deuxième page _page2.html_.
Le Code 1.6 présente le code de notre serveur web modifié. La première modification est l'ajout d'une deuxième page web. Pour cela, nous avons ajouté une condition dans le traitement des requêtes. Si le chemin web de la requête est page2 alors le serveur renvoie le code HTML de la deuxième page. Sinon, il renvoie le code HTML de la première page.
const fs = require("fs");
const http = require("http");
const port = 8080;
const server = http.createServer();
server.on("request", (req, res) => {
if (req.url === "/page2") {
res.end(fs.readFileSync("./page2.html", "utf-8"));
} else {
res.end(fs.readFileSync("./index.html", "utf-8"));
}
});
server.listen(port, () => {
console.log("Server running");
});
Code 1.6 : Le code source modifié server.js du plus petit serveur web.
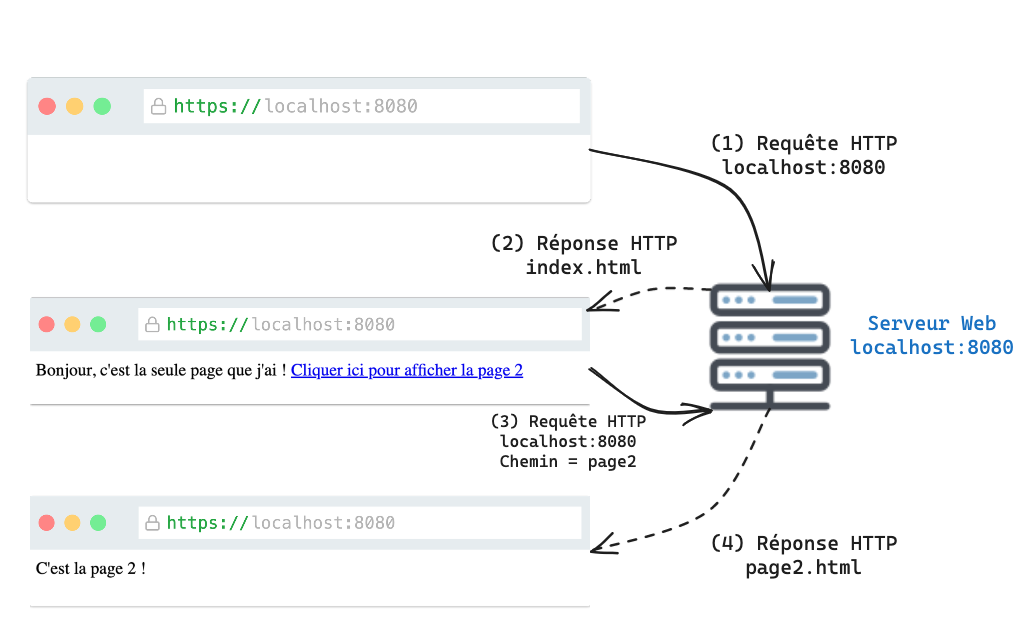
Figure 1.3 : Les requêtes entre le navigateur et le serveur web.
La Figure 1.3 illustre l'interaction entre un navigateur web et le serveur web lors de l'utilisation de ces deux pages web. Dans un premier temps il faut ouvrir un navigateur web et saisir l'URL http://localhost:8080.
Le navigateur envoie une requête HTTP vers le serveur web et celui-ci renvoie le HTML contenu dans le fichier index.html
Lorsque le navigateur reçoit ce HTML, il effectue un rendu graphique (notamment le texte dans la balise <a> s'affiche en bleu).
Si on clique sur le texte bleu, le navigateur envoie une nouvelle requête HTTP avec cette fois une URL qui pointe vers la page2. Le serveur web reçoit cette requête et retourne le HTML contenu dans le fichier page2.html. Le navigateur peut alors afficher la deuxième page.
Ce chapitre présente les concepts de base du web. Il faut retenir les trois points suivants :
- Il faut en effet bien comprendre que les pages web sont composées de ressources qui sont fournies par des serveurs web. Le développement d'un site web passe donc par le développement des pages web mais aussi du serveur qui gère les requêtes des navigateurs web.
- Nous avons vu la notion d'URL qui sert à localiser les ressources web. L'URL est utilisée par le navigateur pour exprimer sa demande (quelle page web il veut visualiser) et par le serveur web pour retrouver le fichier correspondant (nous verrons par la suite que les pages web sont bien souvent générées à partir des paramètres contenus dans l'URL).
- Enfin, nous avons brièvement abordé le fait que les navigateurs web et les serveurs web communiquent via Internet en utilisant le protocole HTTP.
Pour s'exercer
Questions de cours
Qu'est-ce qu'un serveur web ?
- a) Un programme qui s'exécute sur un ordinateur et qui fournit des ressources (HTML, CSS, Javascript, Image, son, etc.) via le protocole HTTP.
- b) Un ordinateur qui permet au navigateur web d'accéder à des pages web.
- c) Un système de fichiers dans lequel sont stockées des pages web.
Qu'est-ce qu'un navigateur web ?
- a) Un programme qui permet d'afficher des pages web en accédant aux ressources fournies par les serveurs web.
- b) Un programme qui permet d'ouvrir des pages HTML.
- c) Un programme qui permet de construire des pages HTML.
Qu'est-ce qu'une page web ?
- a) Un fichier HTML que l'on peut ouvrir dans un navigateur.
- b) Un fichier fourni par un serveur web.
- c) Quelque chose qui a pour vocation d'être affichée par un navigateur web et qui est composée de plusieurs ressources fournies par des serveurs web.
Qu'est-ce qu'une URL ?
- a) L'adresse précise d'une ressource qui est fournie par un serveur web.
- b) L'adresse d'une page web.
- c) L'adresse d'un serveur web.
Qu'est-ce que le protocole HTTP ?
- a) Un standard qui explique la façon dont communique un navigateur web et un serveur web.
- b) Un standard qui explique comment télécharger des pages web.
- c) Un standard qui explique la structuration des pages web.
Réponses : 1-a, 2-a, 3-c, 4-a, 5-a
Exercice 1 - Mur de liens vers des pages web
L'objectif est de créer une application web qui propose une seule page contenant des liens vers toutes les pages que vous trouvez intéressantes.
Créez un répertoire chapitre1-ex1 dans lequel vous allez créer deux fichiers : server.js et index.html. Le fichier server.js contiendra le code de votre serveur web. Le fichier index.html contiendra le code de la page web.
Codez le serveur server.js pour faire en sorte que le serveur web fournisse la page index.html quelque soit la requête envoyée au serveur.
Codez la page web index.html pour faire en sorte qu'elle affiche une référence (balise
<a>) vers https://vanillacademy.com.Choisissez les URL de 2 pages web que vous trouvez intéressantes et ajoutez ces URL dans la page index.html.
Exercice 2 - Lien vers des ressources cachées
Pour cet exercice, vous allez travailler sur le processus de découverte d'URL et d'intégration de lien qui peuvent être cachés sur un serveur distant.
Créez un répertoire chapitre1-ex2 dans lequel vous allez créer deux fichiers : server.js et index.html. Le fichier server.js contiendra le code de votre serveur web. Le fichier index.html contiendra le code de la page web.
Codez le serveur server.js pour faire en sorte que le serveur web fournisse la page index.html quelque soit la requête envoyée au serveur.
Codez la page web index.html pour faire en sorte qu'elle affiche une référence (balise
<a>) vers l'image de la fille en bleu de la page Page exercice.Regardez le code source de la page Page exercice et trouvez le lien vers l'image du 4 juin 2023 qui a été commenté. Ajoutez ce lien à votre page index.html.
La page Page exercice fait des liens vers 10 pages mais il manque un lien vers l'une de ces pages. Retrouver ce lien et intégrez le dans votre page index.html
Projet - Mur d'images
Nous allons commencer la réalisation de notre projet. Il s'agit de développer une application web permettant d'afficher des images. Cette application web va être composée d'une page d'accueil (index.html) et d'un mur d'images (images.html) qui va contenir des liens (balise HTML <a>) vers trois fichiers images contenues dans le répertoire images.
Vous pouvez voir le résultat attendu ici.
- Créez un répertoire chap1-projet dans lequel vous allez créer trois fichiers : server.js, index.html et images.html. Le fichier server.js contiendra le code de votre serveur web. Les fichiers index.html et images.html contiendront le code de vos deux pages web.
- Téléchargez le fichier image.zip. Dézippez le et sauvez trois images de votre choix dans un répertoire que vous nommerez images sous le répertoire chap1-projet.
- Codez le serveur web server.js pour qu'il fournisse la page images.html via l'URL images, les trois images via les URL image1, image2 et image3. De plus, tout autre choix d'URL retourne la page index.html.
- Codez la page images.html. Elle contient une liste de trois liens (balise HTML
<ul>,<li>et<a>) vers les 3 images contenues dans le répertoire images. Chaque lien pointe vers une image. - Codez la page index.html. Elle va contenir un lien (balise HTML
<a>) vers la page images.html.